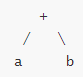go ast go的官方库提供了几个包,可以帮我们解析go的源文件,主要有:
通过解析源文件,我们可以得到ast(抽象语法树)。
而通过遍历ast,我们可以得到源码中声明的结构体、方法、类型等等信息,并根据实际需要生成具体的代码 ,比如自动生成tag,模板方法、手动实现泛型效果等。而且,go的注释在解析时是可以保留的,这就可以实现java中类似annotation的功能,比如根据注释自动生成接口文档(beego的swagger文档生成 ),根据注释提取接口权限信息实现统一权限校验等。
解析过程:
词法分析,将源代码分割成一个个token -> 语法分析,根据go语言的文法 对token流进行规约/推导 -> 生成ast
ast: 抽象语法树 ast是源代码结构的一种抽象表示,以树状形式来表达编程语言的语法结构。
比如表达式 a+b,对应的ast为:
对应使用go表示的结构:
1 2 3 4 5 6 7 8 9 10 *ast.BinaryExpr { . X: *ast.Ident { . . Name: "a" . . } . } . Op: + . Y: *ast.Ident { . . Name: "b" . } }
源码解析 首先要知道具体的接口怎么用,才知道源码从哪个入口开始看是吧
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package mainimport ( "go/ast" "go/parser" "go/token" "log" ) func main () fset := token.NewFileSet() f, err := parser.ParseFile(fset, "./main.go" , nil , parser.ParseComments) if err != nil { log.Fatal(err) } ast.Print(fset, f) }
首先来看第12行代码,这里创建了一个FileSet,顾名思义,FileSet就是源文件集合,因为我们一次解析可能不止解析一个文件,而是一系列文件。
FileSet最主要的用途是用来保存token的位置信息,每个token在当前文件的位置可以用行号,列号,token在当前文件中的偏移量这三个属性来描述,使用PositionFileSet中保存所有token的Position信息,而在ast中,只保存一个Posast的时候,我们需要使用Pos索引向FileSetPosition。
现在来看一下14行parser.ParseFile这个方法,这个方法实现了语法分析:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 func ParseFile (fset *token.FileSet, filename string , src interface {}, mode Mode) (f *ast.File, err error) if fset == nil { panic ("parser.ParseFile: no token.FileSet provided (fset == nil)" ) } text, err := readSource(filename, src) if err != nil { return nil , err } var p parser defer func () ... }() p.init(fset, filename, text, mode) f = p.parseFile() return }
先来简单看一下parser.init方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func (p *parser) init (fset *token.FileSet, filename string , src []byte , mode Mode) p.file = fset.AddFile(filename, -1 , len (src)) var m scanner.Mode if mode&ParseComments != 0 { m = scanner.ScanComments } eh := func (pos token.Position, msg string ) p.scanner.Init(p.file, src, eh, m) p.mode = mode p.trace = mode&Trace != 0 p.next() }
其中,注释有两种:
第一种是注释独自自己占一到多行的,后一种则是跟语句在同一行。parser.next方法中,读取token时,如果遇到第一种注释,会保存到parser.leadComment,如果是第二种注释,则保存到parser.lineComment中,最终会保留到具体的ast中的节点中。
接着来看一下parser.parseFile
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 func (p *parser) parseFile () *ast .File if p.errors.Len() != 0 { return nil } doc := p.leadComment pos := p.expect(token.PACKAGE) ident := p.parseIdent() if ident.Name == "_" && p.mode&DeclarationErrors != 0 { p.error(p.pos, "invalid package name _" ) } p.expectSemi() if p.errors.Len() != 0 { return nil } p.openScope() p.pkgScope = p.topScope var decls []ast.Decl if p.mode&PackageClauseOnly == 0 { for p.tok == token.IMPORT { decls = append (decls, p.parseGenDecl(token.IMPORT, p.parseImportSpec)) } if p.mode&ImportsOnly == 0 { for p.tok != token.EOF { decls = append (decls, p.parseDecl(declStart)) } } } p.closeScope() assert(p.topScope == nil , "unbalanced scopes" ) assert(p.labelScope == nil , "unbalanced label scopes" ) i := 0 for _, ident := range p.unresolved { assert(ident.Obj == unresolved, "object already resolved" ) ident.Obj = p.pkgScope.Lookup(ident.Name) if ident.Obj == nil { p.unresolved[i] = ident i++ } } return &ast.File{ Doc: doc, Package: pos, Name: ident, Decls: decls, Scope: p.pkgScope, Imports: p.imports, Unresolved: p.unresolved[0 :i], Comments: p.comments, } }
上面的decl,包括全局的变量声明,类型声明,函数声明等,具体就不展开了。
来个例子 现在来实现一个自动生成tag的例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 func main () args := os.Args[:len (os.Args)] if len (args) < 4 { log.Fatal("参数:文件路径,行号,列号" ) } fpath := args[1 ] lineNum, err := strconv.Atoi(args[2 ]) if err != nil { log.Fatal("incorrect line number" ) } if err != nil { log.Fatal("incorrect column number" ) } fset := token.NewFileSet() f, err := parser.ParseFile(fset, fpath, nil , parser.ParseComments) if err != nil { log.Fatal("failed to parse file: " , err.Error()) } var target *ast.StructType ast.Inspect(f, func (node ast.Node) bool st, ok := node.(*ast.StructType) if !ok || st.Incomplete { return true } begin := fset.Position(st.Pos()) end := fset.Position(st.End()) if begin.Line <= lineNum && end.Line >= lineNum { target = st return false } return true }) if target != nil { genTag(target) fd, err := os.OpenFile(fpath, os.O_TRUNC|os.O_RDWR, 0777 ) if err != nil { log.Fatal(err) } defer fd.Close() err = format.Node(fd, fset, f) if err != nil { log.Fatal(err) } } }
接着来看一下genTag方法,该放方法主要就是遍历声明的字段,为其生成tag然后设置到ast中对应的node上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 func genTag (st *ast.StructType) fs := st.Fields.List for i := range fs { var ( tag string ) fd := fs[i] if len (fd.Names) > 0 { name := fd.Names[0 ].Name if !isExport(name) { continue } tag = genKey(name) } switch t := fd.Type.(type ) { case *ast.Ident: if tag == "" && isExport(t.Name) { tag = genKey(t.Name) } case *ast.StructType: genTag(t) } var tagStr string if fd.Tag != nil { tagStr = fd.Tag.Value } tags, err := parseTag(tagStr) if err != nil { log.Fatal(err) } change := false if _, ok := tags.Lookup("json" ); !ok { tags.Append("json" , tag) change = true } if _, ok := tags.Lookup("form" ); !ok { tags.Append("form" , tag) change = true } if change { tagStr = tags.TagStr() if fd.Tag == nil { fd.Tag = &ast.BasicLit{} } fd.Tag.Kind = token.STRING fd.Tag.Value = tagStr } } }
完整代码