mysql概览
我们知道,mysql的主要瓶颈在于磁盘IO,而对磁盘IO的一个优化就是使用缓存,将被频繁被访问的数据缓存到内存中,在InnoDB存储引擎中,这样一个用于缓存数据的结构就是BufferPool,缓存的最小单位是Page。
缓存只能解决数据的读取问题,而对于数据的写入呢?通常是使用WAL (write-ahead logging)。我们知道,硬盘IO分为随机IO和顺序IO。机械硬盘的IO的时间主要花费在磁头的寻道上,这是一个比较慢的机械过程,因此随机写很慢,而对于顺序写来说,磁头大多数时间是固定的,因此顺序写非常快。而对于固态硬盘来说,虽然原理不一样,但是顺序写一样比随机写快。WAL的原理是,对于写操作,只需要更新缓存中的Page,并将其标记为脏页,同时输出Page的变更日志,只要将这些变更日志写到磁盘上,这次写操作就完成了。后续如果数据库宕机了,而缓存中的脏页还没有同步到磁盘中,就可以使用变更日志来恢复。而变更日志是顺序写操作,速度非常快。通常,后台还需要有线程定时将缓存中的脏数据刷回磁盘。当一个Page被连续修改多次,最后只需要一次随机写将其刷回磁盘,可以看到该机制还可以减少磁盘随机IO的次数。在InnoDB中,WAL的就是redo log。
InnoDB使用BufferPool来缓存表空间中的Page,使用redo log来保证Page写操作的持久性。
InnoDB中,索引分为簇族索引 (clustered index) 和 辅助索引 (secondary index)。簇族索引就是按照每张表的主键构造的一颗B+树,同时叶子节点存放的表的行记录数据。而辅助索引的叶子节点只包含索引列以及主键。当查询辅助索引时,如果还需要获取记录的其他列,就要拿这个主键到簇族索引查询完整的记录,这个过程叫做回表查询。
当执行写操作时,最终修改的是簇族索引。而对于辅助索引,如果每次写操作,如果它的Page还没有加载到内存的话,都从磁盘将其加载到内存进行修改的话,那么效率可想而知,而且都是磁盘的随机读。因此,InnoDB引入了 change buffer。当执行写操作时,如果对应的辅助索引的Page还没有加载到内存中,就将这个更新操作先写到change buffer中,等到这个Page被加载到内存时,再进行合并,注意change buffer只缓存对叶子节点的更新。还有,如果是唯一索引,因为写操作需要先判断唯一性,需要将其加载到内存中,既然已经加载到内存了,那就不需要change buffer了。change buffer本身也是一颗B+树,它会被存储到共享表空间中,也需要在内存中进行缓存,change buffer本身就是Buffer Pool的一部分,默认占BufferPool的1/4的内存,它的写也会产生redo log。
BufferPool
由于CPU速度和磁盘速度之间的鸿沟,基于磁盘的数据库系统通常使用缓冲池技术,来提高数据库的整体性能。
缓冲池简单来说就是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库整体的影响。
缓冲池的作用就是用来缓存读取的页。当要访问一个页的时候,只有当这个页不在缓冲池时才需要去磁盘中读取,然后会将其放在缓冲池中。而对于写操作,首先会修改在缓冲池中的页,并将其标记为脏页,这些脏页会通过Checkpoint机制以一定的频率刷回磁盘。
Buffer Pool的大小直接影响着数据库的整体性能。可以通过参数innodb_buffer_pool_size来设置缓冲池的大小,如果是专门的mysql服务器,一般需要将80%的内存用于BufferPool。
Buffer Pool中缓存的页类型有:
- 索引页
- 数据页
- undo页
- change buffer
- 自适应哈希索引
- innodb存储的锁信息
- 数据字典信息
从InnoDB1.0.x版本开始,允许有多个BufferPool实例,每个page根据哈希值平均分配到不同的实例中。这样的好处是减少并发冲突,提高数据库的并发处理能力,可以通过参数innodb_buffer_pool_instances来进行配置,默认为1。
用户可以通过information_schema.INNODB_BUFFER_POOL_STATS来观察BufferPool的状态:
1 | mysql> SELECT POOL_ID, POOL_SIZE, FREE_BUFFERS, DATABASE_PAGES, HIT_RATE FROM information_schema.INNODB_BUFFER_POOL_STATS\G; |
这里有个重要的观察指标HIT_RATE,表示缓存的命中率,通常该值不应该小于95%,如果小于该值,则需要观察是否存在比较耗时的全表扫描导致缓存污染。
既然是缓冲池,那么就有缓存淘汰算法。
比较经典的缓存淘汰算法是LRU,但是LRU具有一定的局限性,比如偶然执行一个全局扫描,很容易就会把缓存中的热数据都淘汰掉。
BufferPool中使用的是改进版的LRU内存淘汰算法:
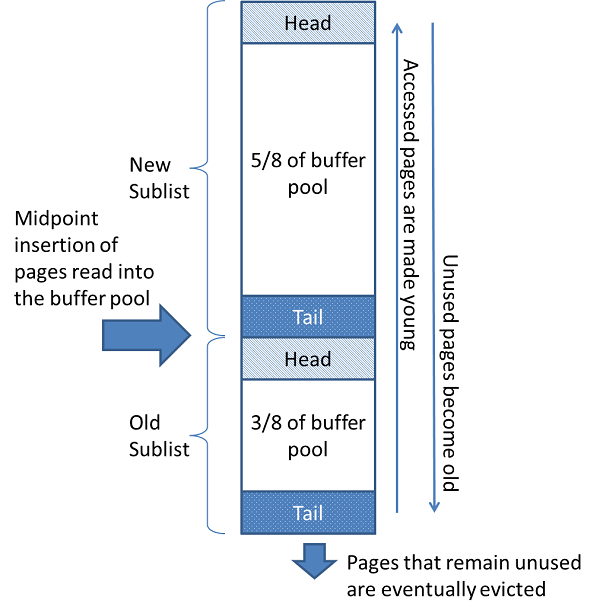
首先,buffer pool中缓存的page会组织成链表,并且分为new和old这两个sub list,并且new的表尾与old的表头相连接,new和old的比例默认是5:3,这个比值由参数innodb_old_blocks_pct进行控制,默认是37,也就是3/8。
当添加一个page到buffer pool时,会将其添加到old的表头。
当一个page添加到buffer pool之后,只有在指定的时间间隔之后被再次被访问到,才会将其移动到new的头部,这个时间间隔由参数innodb_old_blocks_time指定,默认值为1000,单位是ms,也就是一个page被加入到buffer pool 后,只有在经过1s之后再次被访问到,才会将其移动到new的头部。之所以要有这么一个block time,这是因为在一个事务中,一个page经常会被重复扫描。
一直没被使用的page慢慢被移动到old的尾部,最后被淘汰掉,当一个page被淘汰的时候,如果这个page被标记为脏页,需要刷回磁盘。
redo log
上面说到,对于写操作,修改的是buffer pool中的page,并标记为脏页,并不会立即刷回磁盘。而为了数据的持久化,这时候会采用WAL策略,即更新内存的page同时,会产生redo log,当提交事务时,只需要确保该事务对应的redo log落盘。后续如果数据库崩溃重启,可以通过redo log进行恢复。
redo log由两部分组成:
- 内存中的日志缓冲(redo log buffer),这部分是易丢失的
- 重做日志文件(redo log file),这部分是持久的
当事务写redo log时,会先将其写入到redo log buffer中,并在根据下面规则刷新到磁盘:
- 事务提交时
- 当log buffer中有一半的内存空间已经被使用了,这个时候只会执行write,并不会执行fsync
- master thread定时刷盘
redo log buffer可以通过参数innodb_log_buffer_size配置缓冲区大小,默认为8MB。
注意,redo log buffer是所有事务线程共用的,一个事务即使还没有提交,它的redo log也可能被刷回到磁盘文件中。
redo log按照512字节为单位进行存储,也就是说重做日志缓存、重做日志文件都是以块(block)的方式进行保存,称作重做日志块(redo log block)。因为重做日志块的大小与磁盘扇区大小一致,都是512字节,因此重做日志的写入可以保证原子性,不需要采用doublewrite技术。
redo log记录的是page的物理变更,因此它是物理日志,是幂等的:f(f(x))=f(x)。
为了保证事务的持久性,在事务提交时,需要确保redo log落盘,这需要调用一次fsync操作,因此磁盘的性能决定了事务的提交性能,也就是数据库性能。
当然,用户也可以通过修改参数innodb_flush_log_at_trx_commit来修改事务提交时是否落盘重做日志,这个参数有3个值:
- 0:事务提交时不对redo log进行处理,仍然将其保留在redo log buffer中。master thread会定时每秒将redo log buffer中的内容落盘,也就是执行write和fsync。
- 1:默认值,表示事务提交时必须执行write和fsync,保证当前事务的redo log都落盘。
- 2:表示事务提交时只执行write,但是不执行fsync操作,因为重做日志文件没有使用O_DIRECT选项,会写入到操作系统的file cache中。在这个设置下,只要操作系统不宕机事务就不会丢失。
如果对数据的持久性有严格要求,则必须将其设置为1。
每个InnoDB存储引擎至少有1个重做日志文件组,每个文件组下至少有2个重做日志文件,如默认的ib_logfile0和ib_logfile1。为了得到更高的可靠性,用户可以设置多个的镜像日志组,将不同的文件组放在不同的磁盘上,以提高重做日志的高可用性。在日志组中每个重做日志文件的大小一致,并以循环写入的方式运行。InnoDB先写重做日志文件1,当达到文件的最后时,会切换到重做日志文件2,再当重做日志文件2也被写满时,会再切换到重做日志文件1中。
与重做日志文件相关的参数配置:
1 | [mysqld] |
重做日志文件的大小设置对于InnoDB存储引擎的性能有很大影响。一方面重做日志文件不能设置太大,否则恢复时可能需要很长时间;另一方面,又不能设置太小,否则可能导致一个事务的日志需要多次切换重做日志文件。此外,重做日志文件太小会导致频繁地发生async checkpoint,也就是将部分脏页写会磁盘,导致性能抖动。
LSN
LSN是log sequence number的缩写,即日志序列号。
在InnoDB存储引擎中,LSN占用8字节,并且单调递增。
LSN的用途有:
- 重做日志写入的总量:例如lsn原本为1000,有个事务写入了100字节的重做日志,那么lsn就变为了1100
- checkpoint的位置
- 页的版本:每个页的头部,都有一个FIL_PAGE_LSN字段,记录了该页的lsn,表示该页最后刷新时lsn的大小。可以通过该字段来判断页是否需要进行恢复操作。
查看innodb的状态:
1 | mysql> SHOW ENGINE INNODB STATUS\G; |
可以看到:
- log sequence number:表示当前的lsn
- log flushed up to:已经刷到磁盘的lsn
- pages flushed up to:已刷到磁盘的页的lsn
- last checkpoint at:最后一次检查点的位置,表示对应更新已经刷新到磁盘的lsn,当执行恢复操作时,只要恢复从该lsn开始的redo log
checkpoint技术
前面说到,写操作会产生redo log,事务提交时需要把redo log落盘。这些redo log需要等到对应的page已经刷回磁盘,才可以删除。
Checkpoint技术是将脏页刷回磁盘,它的目的是解决:
- 缩短数据库的恢复时间:数据恢复过程就是redo log的重放过程,如果redo log太多,则恢复的时间需要很长
- 缓冲池不够用时,将脏页刷新到磁盘:当BufferPool中某个页被淘汰时,如果是脏页,需要刷回磁盘
- 重做日志文件满了之后,刷新脏页,释放空间
在InnoDB中有两种Checkpoint,分别为:
- Sharp Checkpoint:在数据库关闭时将所有脏页都刷回磁盘,这是默认工作方式,即参数
innodb_fast_shutdown=1 - Fuzzy Checkpoint:innodb内部用于脏页的刷新,推进checkpoint,每次只刷新一部分脏页
BufferPool中Page的三个状态:
- free:空闲状态,也就是该页并没有被使用
- clear:lru中没有脏数据的页
- dirty:lru中被修改过,并且还没有被刷回磁盘的页
BufferPool中的三个链表:
- lru list:用于执行改进版本的lru算法,当需要淘汰Page时,选择链表尾部的Page
- free list:BufferPool中可用的空闲页,每次从磁盘读取一个新的Page到BufferPool中时,都需要分配一个空闲页。假设free list为空,那么每次都需要先从lru list的尾部淘汰Page,执行必要的脏写回操作,这是比较耗时的。因此InooDB总是会维持free list有足够多的空闲页。在mysql5.6.2之前,每当从磁盘读取一个新的Page到BufferPool时,都会检查一下freeList是否有足够的空闲页,如果没有则会从LruList尾部淘汰部分Page加入到free list中。因为这个检查是在用户查询线程执行的,会阻塞用户操作,从mysql5.6.2版本开始,这部分操作被移动到了独立的后台pageCleaner线程,pageCleaner线程会每秒执行一次lru list flush操作,保证free list有足够多的空闲页。
- flush list:BufferPool会把脏页按照最早修改时间(oldest_modification)进行排序,oldest_modification越小,说明page被修改的时间越早,就排到flush list的越后面。当InnoDB执行fuzzy Checkpoint时,会从flush list尾部开始,刷一些脏页回磁盘,然后推进checkpoint,这些脏页对应的redo log就可以被覆盖掉了。从mysql5.6.2开始,对flush list 的 flush操作也移动到了pageCleaner线程中了。
从上面可以看到后台pageCleaner线程,定时执行:
- lru list flush:从lru list尾部开始扫描,主要是为了回收Page到free list,维持足够多的空闲页
- flush list flush:从flush list的尾部开始扫描,主要是为了刷脏页,推进checkpoint,这些page不会被回收
与刷脏页相关的一些参数:
| 参数 | 含义 |
|---|---|
| innodb-lru-scan-depth | 后台pageCleaner线程在每个BufferPool实例的lru list中要扫描(从尾部开始扫描)多少个page,该变量也控制可用页的数量。该线程每秒触发一次;默认值为1024,通常可以调小该值,尤其是在写密集的场景下。 |
| innodb_flush_neighbors | 当刷新一个page时,是否需要检测该页所在区的所有页,如果是脏页则一起进行刷新。这样做的好处,可以通过AIO将多个IO写入合并成一个IO操作,在传统的机械硬盘下有显著优势,默认开启。如果是固态硬盘,则建议关闭。 |
| innodb_max_dirty_pages_pct | 当脏页比例达到该值时,刷新一部分脏页回磁盘 |
| innodb_io_capacity | 定义innodb后台线程可用的IOPS,默认200 |
| innodb_io_capacity_max | 如果flushing activity落后比较多,innodb可用更加主动地执行flush,使用比innodb_io_capacity指定的更大的IOPS,该参数指定这种场景下的最大IOPS。默认2000。 |
当重做日志文件不可用,也就是“满了”,这时候也会触发checkpoint,执行刷脏页操作。
将已经写入到重做日志的lsn记为redo_lsn,将已经刷回磁盘最新页的lsn记为checkpoint_lsn,
则可定义:
1 | checkpoint_age = redo_lsn-checkpoint_lsn |
假如我们一个重做日志文件组有两个文件,每个文件大小为1GB,则total_redo_log_file_size为2GB。
当async_water_mark < checkpoint_age < sync_water_mark时,会触发AsyncFlush。
当sync_water_mark < checkpoint_age时,会触发SyncFlush,这种情况一般很少出现。
在innodb1.2.x版本之前,AsyncFlush会阻塞发现问题的用户查询线程,而SyncFlush会阻塞所有的用户查询线程。从innodb1.2.x版本开始,这部分刷新操作同样放到了PageCleaner线程,因此不会阻塞用户线程。
double write
InnoDB中,每个Page的大小默认为16KB,而磁盘的读写基本单位是扇区,也就是一次读写512个字节。
当正在把一个脏页写回磁盘的时候,如果只写了前面4KB的内容,这时候数据库宕机了,这种情况被称部分写失效。在这种情况下,这个页本身已经被损坏了,即使通过redo log也无法进行恢复。因为redo log记录的是Page变更的物理操作。而一个Page除了存储数据之外,在Page的头部还存储了元数据,包括页的lsn和checksum,并且还在Page的尾部存储了checksum和lsn。InnoDB可以通过将Page尾部的两个字段与头部中对应的字段进行比较,来判断这个Page的完整性。
InnoDB通过double write来保证数据页的可靠性。
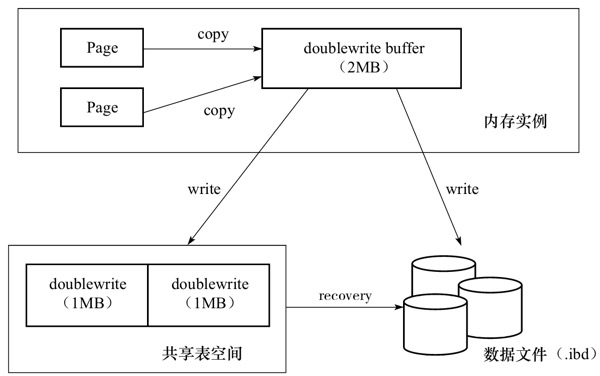
doublewrite由两部分组成,一部分是内存中的doublewrite buffer,大小为2MB,另一部分是物理磁盘上面共享表空间中连续的128个页,即两个区,大小同样为2MB。
在刷新脏页时,首先通过memcpy函数将脏页复制到内存的doublewrite buffer中,然后通过该buffer分两次,每次1MB顺序地写入到磁盘的共享表空间中,然后马上调用fsync函数,同步磁盘。因为共享表空间中的页是连续的,顺序写的开销不是很大。在完成对doublewrite的Page写后,在把doublewrite buffer中的页写入到各个表空间文件中,此时的写入是随机IO。
假如在写到doublewrite的页的时候,数据库宕机了,这时候我们还没有将脏页写回数据文件,直接通过redo log就可以恢复;
假如在写脏页到数据文件的过程宕机了,这时候我们可以在共享表空间的doublewrite中找到对应的页副本并进行恢复。
而且,刷脏页的时候,先将其拷贝到doublewrite buffer,这个过程是内存操作,很快的,之后的脏页写回直接访问buffer,不影响用户线程对这个Page后续的访问。
可以同过命令查看doublewrite的状态:
1 | mysql> SHOW GLOBAL STATUS LIKE 'innodb_dblwr%'\G; |
- Innodb_dblwr_pages_written:doublewrite写入的页
- Innodb_dblwr_writes:实际写入次数
如果系统在高峰时,innodb_dblwr_pages_written/innodb_dblwr_writes远小于64,说明系统写入压力并不是很高。这个64是怎么来的呢?doublewrite buffer的大小是2MB,一个Page的大小是16KB,也就看可以存储128个Page,而doublewrite buffer需要写2次。
可用通过参数skip_innodb_doublewrite来禁用该功能。
有些文件系统本身就提供了部分写失效的防范机制,比如ZFS文件系统,在这种情况下,就不需要启用double write了。
自适应哈希索引
InnoDB存储引擎会监控对表上各索引页的查询。如果观察到建立哈希索引可以带来速度提升,则会自动建立哈希索引,称之为自适应哈希索引(Adaptive Hash INdex, AHI)。
AHI是通过对Buffer Pool中的B+树的Page构造而来的,因此建立的速度很快,而且不需要对整张表构建哈希索引。
AHI有一个要求,即对这个Page的连续访问模式必须是一样的,这里的访问模式是指查询的条件一样。
而且哈希索引只能用来搜索等值的查询,而对于像范围查找这种就无法使用。
AHI实际上就是在查询条件和Page之间创建哈希索引,根据查询条件,能够快速找到要访问的Page。
可以在show engine innodb status的输出中查看AHI的统计信息。
默认AHI是开启的,可以通过参数innodb_adaptive_hash_index将其禁用。
binlog
binlog是由mysql server提供的,记录了对数据库的所有更改操作,包括DDL和DML操作,但不包括SELECT和SHOW这类操作,因为这类操作没有对数据进行修改,即使是SELECT FOR UPDATE,也不会被记录到binlog中。
而对于update语句,即使执行的changed为0,该语句也可能会被写到binlog中。
如果用户想要记录select和show操作,应该使用查询日志(general log),而不是二进制日志。
总的来说,binlog主要由以下几种作用:
- 数据恢复:使用binlog执行point-in-time的恢复
- 复制:mysql的主从复制,或者实时同步到其他类型的存储系统
- 审计:可以对binlog中的信息进行审计,判断是否有对数据库进行注入攻击
与binlog相关的配置主要如下:
1 | mysql> vim /etc/mysql/my.cnf |
binlog的写入
binlog是由mysql server产生的一种逻辑日志。
当一个线程开始一个事务时,mysql会自动分配一个binlog cache,大小由参数binlog_cache_size决定,该值如果设置过大,会增加mysql的内存占用,而如果设置过小,当一个事务产生的binlog超过了cache的大小,mysql会把cache中的日志写到一个临时文件中。可以通过命令SHOW GLOBAL STATUS查看binlog_cache_use和binlog_cache_disk_use两个状态值,判断当前binlog_cache_size的设置是否合理
每个事务产生的binlog在binlog文件中是连续的。一个事务运行过程中,产生的binlog都会先写到它的binlog cache中。等到事务提交的时候,才将其写到binlog文件中。
默认情况下,binlog日志并不是在每次写binlog文件的时候都执行fsync,因此当数据库所在操作系统宕机时,可能会有一部分数据没有写入binlog文件中,这会给恢复和复制带来问题。
参数sync_binlog=[N]表示每多少次将binlog cache的日志写到binlog文件,就执行一次fsync。该值默认是0,表示mysql不会执行fsync,由文件系统自己控制它的file cache的刷新。最安全的配置是将其设置成1,表示每次提交事务的时候,都会执行fsync把binlog刷新到磁盘上。
因为是在事务提交的时候,才会把binlog cache中的内容写到binlog文件,每个事务自己的binlog在binlog文件中都是连续的,而且,先提交的事务的binlog会先写入到binlog文件中。在主从复制的时候,可能slave中事务的启动顺序和在master的启动顺序并不一致,在某些情况下会导致主从不一致的问题。
binlog的格式
在mysql5.1之前,binlog都是基于sql语句进行记录,也就是使用STATEMENT格式。如果sql中包含rand、uuid等函数,或者使用触发器等操作,都可能会导致主从之间的数据不一致。
而且当InnoDB使用READ COMMITED隔离级别,会出现类似丢失更新的现象,从而出现主从之间的数据不一致,我们来看一下MysqlBug23051:
考虑现在有一张表(a, b),该表中的数据有[(10, 2), (20, 1)]
master和slave都使用
READ COMMITED隔离级别在master上有两个session事务:
| session 1 | session 2 |
| —————————— | —————————— |
| begin; | begin; |
| update set a = 11 where b = 2; | |
| | update set b = 2 where b = 1; |
| | commit; |
| commit; | |因为是RC隔离级别,并不会加gap锁,因此session2的事务可以执行成功。当这两个事务提交之后,表中的数据变成了 [(11, 2), (20, 2)]。
因为session2的事务先提交,因此会先写入binlog中,而session1的事务则后写入。
然后binlog被同步到slave,slave会按照binlog的顺序执行事务:
session2 session1 begin; update set b = 2 where b = 1; commit; begin; update set a = 11 where b = 2; commit; 这时候slave的表数据变成了 [(11, 2), (11, 2)]。
可以看到同步之后主从数据不一致了。产生该bug的主要原因是因为RC隔离级别,不会加间隙锁。
解决方法有两种:1. 使用RR隔离级别;2. 使用ROW格式的binlog。
mysql从5.1开始引入了binlog_format参数,可以设置binlog的格式:
STATEMENT:记录逻辑SQL语句,它产生的日志很小,但是可能会导致主从不一致ROW:记录表中行的逻辑变更,能够解决主从不一致的问题,但是产生的日志可能很大,需要更大的binlog cache和磁盘空间MIXED:结合两者的优点,mysql自己会判断执行的sql是否会引起主从不一致,如果会则使用ROW格式,否则使用STATEMENT格式。
binlog_format是动态参数,因此可以在数据库运行环境下进行更改:
1 | mysql> SET @@session.binlog_format='ROW'; # 修改当前会话的binlog格式为ROW |
当我们需要将mysql实时同步到其他类型的存储系统时,比如将mysql的内容同步的redis作为缓存,或者同步到es中提供查询功能等,这时候需要使用ROW格式,目前也有很多工具可以同步、解析ROW格式的binlog,比如canal
我们可以使用参数binlog_row_image来控制mysql输出的ROW格式日志的内容,该参数仅对ROW格式和MIXED格式有效。
这里先解释一下两个术语:
- 前镜像 (before image):行修改前的内容
- 后镜像(before image):行修改后的内容
binlog_row_image可选的值有三个:
FULL: Log all columns in both the before image and the after image.MINIMAL:Log only those columns in the before image that are required to identify the row to be changed; log only those columns in the after image where a value was specified by the SQL statement, or generated by auto-increment.NOBLOB: Log all columns (same as full), except for BLOB and TEXT columns that are not required to identify rows, or that have not changed.
该参数的默认值是FULL。
如果我们使用FULL,当我们操作错误时,可以通过前镜像来执行反向操作,恢复数据,这也就是flashback工具的工作原理。
基于binlog的主从同步
复制 (replication) 是mysql数据库提供的一种高可用高性能的解决方案,一般用来建立大型的应用。
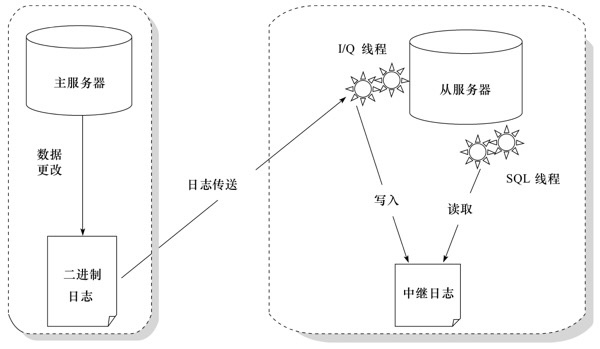
replication的工作原理分为以下3个步骤:
- master把数据的更改记录写到binlog中
- slave把master的binlog复制到自己的中继日志 (relay log)中
- slave重做relay log中的日志,把更改应用到自己的数据库上,达到数据的最终一致性
主备延时
复制不是完全实时地进行同步,而是异步实时。这中间存在主从服务器之间的执行延时。
在slave上面执行show slave status\G命令,返回结果里面会显示seconds_behind_master,表示当前备库延迟了多少秒,这个值的计算方法是这样的:
- 每个事务的binlog里面都有一个时间字段,记录主库上写入的时间
- 备库取出当前正在执行的事务的该时间字段,计算与当前系统时间的差值,得到的就是
seconds_behind_master
当备库连接主库的时候,会计算他们之间系统时间的差值,在计算延时的时候会扣掉这个差值。
在网络正常的情况下,日志从主库传给备库所需的时间非常短。因此网络正常情况下,主备延时的主要来源是备库接收完binlog之后和执行完这个事务之间的时间差。
主备延迟的几种来源:
- 备库机器性能比主库机器性能差导致
- 备库压力大:备库一般会提供一些读能力,读请求压力大,影响了同步速度
- 大事务:binlog只有事务完成之后才会写入到binlog文件中,然后才会同步到slave。比如一个主库上的事务执行了10分钟,那么就可能导致从库延迟了10分钟
- 造成主备延迟还有一个大方向,就是备库的并行复制能力
由于主备延迟的存在,主备切换的时候,就有不同的策略:
- 可靠性优先策略:存在一段时间的不可写状态,等到主备延迟为0的时候再切换
- 可用性优先策略:不等主备延迟为0,直接切换slave为master,这时候原本的relay log还会继续执行,会导致数据不一致
并行复制
在mysql5.6版本之前,mysql只支持单线程复制,也就是只有一个SQL线程在执行中继日志,在主库并发高、TPS高的时候就会出现严重的主备延迟问题。
在master中,多个事务之间通过锁来解决竞争问题,对存在数据竞争的事务之间是有执行顺序的。
在slave中,如果要支持多线程复制,就需要保证存在数据竞争的事务执行顺序,和master的一样,才能保证主从之间的数据一致性。然而这是无法保证的,当两个事务并行的时候,我们无法控制让那个事务获得锁。
因此为了能够提供多线程复制,具有数据竞争的事务就不能并发执行,而是要按照binlog中的顺序串行执行。因为先出现在binlog中的事务是最先完成的,说明该事务先获得了锁。
多主复制
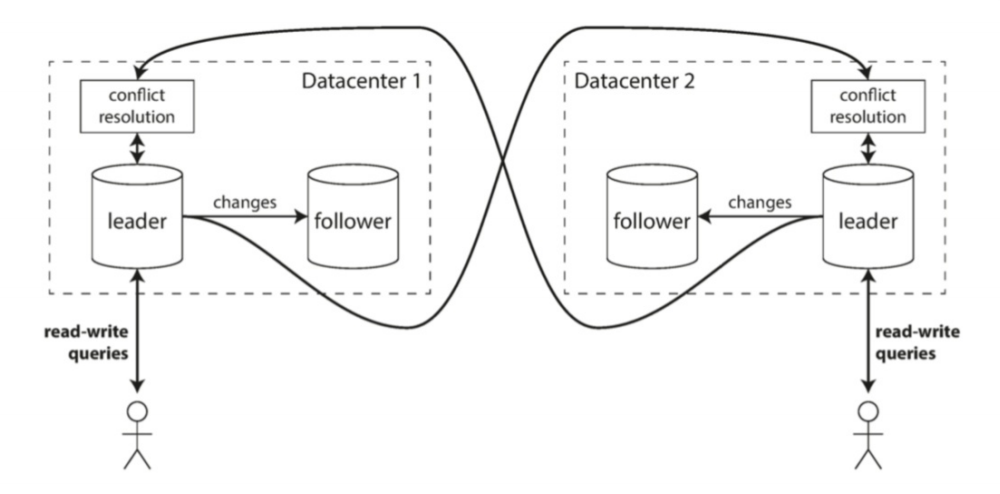
为了容灾,提高系统的可用性,通常会使用多数据中心部署,也就是实现异地多活,这时候通常会使用多主复制。
每个数据中心内部都有一个master,然后多个master之间会同步更新。
每个数据中心有一个master,这样用户就可以就近写入,减少延迟。因为多主写入,可能会有数据冲突的问题,因此一般同一个用户会固定到同一个master写,避免冲突的出现。
多主复制,如果开启了配置log-slave-updates(通常这是需要开启的,以便可以同步到同一个数据中心内的其他slave),那么就会产生循环复制的问题:master1的binlog同步到master2,master2应用完成之后,写入到自己的binlog中,又同步回master1,……
要解决这个问题,一种方法是给每个实例分配一个唯一的标识,也就是通过参数server-id指定,master会在自己的binlog中写入自己的server-id,并且在一个”slave”重放过程中,生成的binlog中的server-id与原binlog的保持一致。每个实例在重放时,先判断binlog中的server-id是否跟自己相同,如果是,表示这个binlog是自己生成的,直接跳过。
还有一种方法是通过GTID。 GTID即全局事务ID (global transaction identifier), 其保证为每一个在主上提交的事务在复制集群中可以生成一个唯一的ID 。每个实例都会记录自己已经执行过的GTID集合。当具有重复GTID的事务时,就会被忽略。
主从切换
[TODO]
当有多个slave,其中一个slave被提升为master,要更改其他slave从新的master进行同步。这时候,需要在新的master的binlog中为每个slave找到一个pos,表示slave要从这个位置开始同步binlog。因为可能有部分binlog,已经从原master复制到该slave的relay log,因此刚开始复制可能存在数据冲突的问题。
通过gtid简化主从切换。开启gtid之后,新的master可以通过slave的gtid集合,自动计算出slave应该开始同步的位置。
查看binlog文件
二进制日志会存储到datadir指定的目录下,默认是/var/lib/mysql/下面,在该目录下可以看到:
1 | $ ls mysql-bin.* |
mysql-bin.index文件是二进制日志文件的索引,用来存储产生的所有二进制文件路径。
我们可以使用mysqlbinlog工具或者使用SHOW BINLOG EVENTS [ IN file]\G命令查看binlog日志。
开启二进制日志会使mysql性能下降约1%,考虑到可以使用复制和point-in-time的恢复,这点性能损失是可以接受的。
redo log与binlog
redo log和binlog初看起来好像非常相似,但是从本质上看,两者有着非常大的不同。
首先,redo log是在InnoDB存储引擎层产生的,而binlog是在mysql server层产生的,并且binlog不仅仅针对于InnoDB存储引擎,任何其他的存储引擎对于数据库的更改都会产生binlog。
其次,两种日志记录的内容形式不同。binlog是一种逻辑日志,主要是用于复制和备份。而redo log是物理格式的日志,是一种WAL,记录每个页的修改,用于做recover,当脏页刷回磁盘,对于的redo log就可以被覆盖掉了。
此外,两种日志的写入磁盘的时间点不同。binlog只在事务提交时才会写入binlog文件,每个事务在文件上的日志都是连续的。而redo log在事务进行过程中是不断的被写入的,其在redo log文件中,多个事务的redo log是交错出现的。
内部xa事务
对于使用innodb存储引擎,redo log总是会产生的,而binlog只有在开启binlog日志的时候才会产生。
当开启binlog之后,提交事务的时候,需要确保binlog与redo log之间事务的状态一致,为此mysql引入了内部xa事务,具体流程如下:
- InnoDB事务进入prepare状态,这时候redo log有prepare标识,将redo log写盘并执行fsync
- binlog写盘,并执行fsync
- InnoDB事务提交,redo log写commit标识,这时候并不需要fsync
1 | graph TD |
binlog中的事务与redo log的事务通过xid进行关联,也就是同一个事务具有相同的xid。
崩溃后的数据恢复流程:
- 如果redo log里面的事务是完整的,也就是已经有commit标识,直接恢复数据,提交事务
- redo log里面的事务只有完整的prepare标识,通过XID到binlog查找对应事务是否存在并提交(日志是否完整):
- 如果是,恢复数据,提交事务
- 否则,回滚事务
1 | graph LR |
可以看到,在redo log中即使事务没有commit标识,只要binlog写入成功,最终也会被提交,因此redo log在写commit标识的时候不需要执行fsync。
group commit
可以看到,当开启binlog之后,提交一次事务就需要执行两次fsync。
为了减缓磁盘压力,mysql引入了group commit,即一次fsync可以刷新确保多个事务日志被写入到文件中。
将内存中日志同步到文件,需要两个步骤:
- 执行write操作,将缓存中的日志写到文件,这时候实际上是写到由操作系统提供的file cache
- 执行fsync,将file cache中的内容同步到磁盘
其中,步骤2相对于步骤1是一个比较慢的过程,因为需要和磁盘打交道。
而对于group commit,就是要延迟步骤2的执行,从而可以有更多的事务执行步骤1,这样每次fsync就可以刷新更多的事务的日志到磁盘,因此内部xa事务的流程变成了:
- InnoDB事务进入prepare状态,这时候redo log有prepare标识,将redo log写文件(file cache)
- 将事务的binlog写到文件中
- 对redo log日志文件执行fsync
- 对binlog文件执行fsync
- InnoDB事务提交,redo log写commit标识,不需要fsync
1 | graph TD |
而对于binlog的group commit (GLGC)的实现方式,具体过程如下图所示:

首先,在mysql数据库上层进行提交时,会按照顺序将其放入一个队列中,队列中的第一个事务称为leader,其他事务称为follower,leader控制folloer的行为。BLGC具体步骤如下三个阶段:
- flush阶段:将每个事务的binlog写入文件,也就是file cache
- sync阶段:执行fsync,将file cache中的内容刷到磁盘。如果队列中有多个事务,那么仅一次fsync就可以完成其binlog的写入
- commit阶段,leader按照顺序调用存储引擎层事务的提交,也就是innodb提交事务,redo log写commit标识
参数binlog_max_flush_queue_time用来控制flush阶段中等待的时间,即延迟进入sync阶段的时间,这样可以让更多的事务加入该group,但是会使得事务的提交响应变慢。该参数默认值为0,且推荐设置依然为0,除非有大量的连接,并且不断地在进行事务的写入更新操作。
在写操作频繁的场景下,group commit的效果尤为明显。
undo log
redo log记录了事务的行为,可以很好的通过对页进行“重做”来恢复数据,保证事务的持久性。但是事务有时还需要进行回滚操作,这时就需要undo log。因此,在执行写操作时,innoDB存储引擎不但会产生redo log,还会产生一定量的undo log。
undo log不仅仅用于回滚事务,还用于实现MVCC,提供快照读。
redo log是存放在重做日志文件中的,而undo log不同,它是存放在数据库内部一个特殊的段(segment)中,这个段称为undo段。undo 段位于共享表空间内。
undo log记录的是逻辑日志,因此只是将数据库逻辑地恢复到原来的样子,所有的修改都被逻辑地取消,但是数据结构和页本身在回滚之后可能大不相同。例如,用户执行了一个插入10w条记录的操作,这个事务会导致分配一个新的段,即表空间会增大。在用户执行ROLLBACK时,会将插入的事务进行回滚,也就是反向执行删除操作,但是表空间的大小并不会因此而收缩。对于事务的回滚,实际上就是根据undo log执行反向操作,对于insert操作执行一个反向的delete,对于每个delete,执行一个反向的insert,而对于每个update,则会执行一个相反的update,还原为修改前的行。
undo log本身也需要进行持久化存储。这是因为在进行崩溃恢复时,对于那些在redo log中处于prepare阶段,而在binlog中并没有提交的事务,需要进行回滚,则这就要求undo log也需要持久化存储。undo log本身就是存储在表空间内的,也是按页进行存储,它也会缓存在BufferPool中,写入的时候和会产生redo log,undo log本身依赖redo log提供持久化保证。
InnoDB存储引擎对undo的管理采用段的方式。首先,InnoDB存储引擎有rollback segment,每个回滚段记录了1024个undo log segment,而在每个undo log segment段中进行undo页的申请。在InnoDB1.1之前,只有一个回滚段,因此支持同时在线的事务限制为1024。从1.1版本开始,InnoDB支持最大128个回滚段,因此支持同时在线事务最大为128*1024,也就是一个undo log segment同一时刻只能分配给一个事务。共享表空间偏移量为5的页记录了所有回滚段header所在的页。
从InnoDB1.2版本开始,可以通过参数对回滚段做进一步的设置:
- innodb_undo_directory:设置回滚段文件所在路径,这意味着回滚段可以存放在共享表空间外的位置,即可以设置为独立表空间。该参数默认为
.,表示当前InnoDB存储引擎的目录 - innodb_undo_logs:设置回滚段的个数,默认值为128,在innodb1.2用于替换之前版本的参数innodb_rollback_segments。
- innodb_undo_tablespaces:用来设置构成回滚段文件的数量,这样回滚段可以较为平均地分布在多个文件中。
当事务提交时,InnoDB存储引擎会做以下两件事情:
- 将undo log放入列表中,以供后续的purge操作:事务提交之后,并不能马上删除undo log以及undo log所在的页,这是因为可能还有其他事务需要通过undo log来实现快照读,也就是需要通过undo log来得到行记录之前的版本,故事务提交时将undo log放入一个链表中,是否可以最终删除undo log及所在页由purge线程来判断
- 判断undo log所在页是否可以重用,如果可以分配给下个事务使用:如果为每个事务分配一个单独的undo页非常浪费空间,特别是OLTP应用类型。因为事务提交时,可能并不能马上释放页,如果TPS比较高,对磁盘空间将会有非常高的要求。因此,innodb在事务提交时,会首先判断undo页的使用空间是否小于3/4,如果是的话将会被重用,之后新的undo log将会被记录在当前undo log之后。
undo log有两种类型:
- insert undo log:在insert过程中产生的undo log。insert操作的记录,只对事务本身可见,其他事务不可见,故该类型的undo log可以在事务提交后直接删除,不需要进行purge操作
- update undo log:记录的是对delete和update操作产生的undo log。该undo log可能需要用于实现MVCC机制,供其他事务用于快照读,因此不能在事务提交时就进行删除。提交时将其放入undo log链表,等待purge线程进行最后的删除。
purge
delete和update操作,并不会真正的删除原来的记录(更新主键列的实现为删除原来的记录并插入新的记录),而只是将记录的delete flag设置为1,即标记删除状态。而真正的删除操作,其实被“延时”了,最终在purge操作中完成。
purge用于完成最终的删除操作。这是因为InnoDB存储引擎支持MVCC,所以记录不能在事务提交时立即进行处理。这时其他事务可能正在引用这行(需要通过快照读读取记录),故InnoDB需要保存记录之前的版本。而是否可以删除该条记录由purge来进行判断。若该行记录已不被任何其他事务引用,那么就可以进行真正的delete操作,并且清除对应的undo log。
上面说过,undo log的page允许重用,也就是可以在一个page上记录多个事务的undo log,并且后开始的事务产生的undo log总是在后面。此外,InnoDB还维护一个history列表,它根据事务提交的顺序,将undo log进行链接
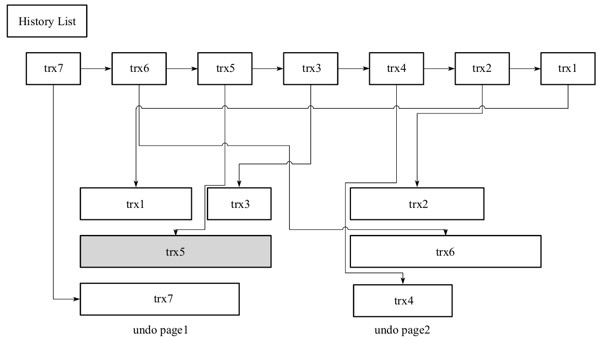
可以看到,history list是按照事务提交顺序将undo log进行组织,先提交的事务总在尾端。因为可以重用,因此一个undo page中可能存放了多个不同事务的undo log。比如在上图中,undo page 1就存放trx1、trx3、trx5、trx7这四个事务的undo log。trx5的灰色阴影表示该undo log还被其他事务引用。
在执行purge的过程中,InnoDB首先从history list中找到第一个需要被清理的记录,这里为trx1,在清理之后,会继续在trx1的undo log所在的undo page中继续寻找是否存在可以被清理的记录,所以接着清理trx3,而在尝试清理trx5时,发现其undo log还被其他事务引用而不能清理,这时候会回到history list中查找,找到trx2,接着在trx2的undo page中找到trx6和trx4。
InnoDB存储引擎这种先从从history list中查找,然后在undo page中查找的设计模式是为了避免大量的随机IO,从而提高purge的效率。
可以使用全局参数innodb_purge_batch_size来设置每次purge操作需要清理的undo page数量。
当innodb存储引擎压力非常大时,无法高效执行purge操作,那么history list的长度会越来越长。可以使用全局参数innodb_max_purge_lag来控制history_list的长度,若长度大于该参数,则会”延缓”DML的操作。该参数默认为0,也就是不限制history list的长度。
change buffer
change buffer是用于缓存辅助索引页的更新的数据结构。当DML需要修改辅助索引,但是辅助索引页不在buffer pool缓冲池中,这时候会先把这个变更记录到change buffer中,等待对应的这个Page被加载的时候,再把更新合并进去。可以看到,change buffer可以减少每次DML的磁盘读写次数。
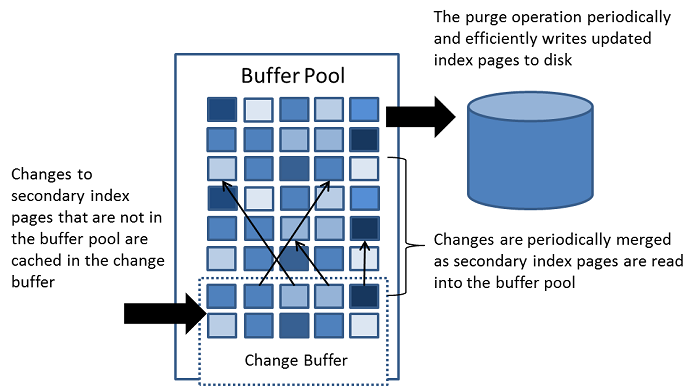
如果辅助索引是唯一索引,因为需要执行唯一性检查,需要加载其page,因此唯一索引无法使用buffer pool。
在内存中,change buffer是buffer pool的一部分,而在磁盘上,change buffer是系统表空间的一部分。change buffer需要持久化到磁盘上,以便宕机的时候不会丢失数据。同样的,change buffer需要使用redo log来保证持久性。
若数据库发生宕机,如果change buffer有大量操作还没有合并,这时候恢复可能需要很长的时间。
可以通过以下参数,对change buffer进行配置:
- innodb_change_buffering:配置change buffer缓存的内容
- all:The default value: buffer inserts, delete-marking operations, and purges.
- none:Do not buffer any operation
- inserts:Buffer insert operations.
- deletes:Buffer delete-marking operations.
- changes:Buffer both inserts and delete-marking operations.
- purges:Buffer physical deletion operations that happen in the background.
- innodb_change_buffer_max_size:配置change buffer占用buffer pool的内存比例;默认值为25,也就是change buffer默认占用buffer pool的1/4,最大可用设置为50
可用通过查看innodb引擎状态来监控change buffer状态信息:
1 | mysql> SHOW ENGINE INNODB STATUS\G |
索引
索引
使用B+树作为索引,B+树具有高扇出性,在数据库中,B+树的高度一般都在2~4层。

数据库的主要瓶颈在磁盘IO,高扇出性意味着B+树的高度不会太高。
InnoDB中,页是最小管理单位,一个页的大小默认是16k(当然也可以通过参数
innodb_page_size进行修改)。假设一张表的主键ID是BIGINT类型,占用8byte,而指针大小为6byte,因此一个索引页可以存放16kb/14byte=1170个索引项,而假设一条记录大小为1kb,那么一颗3层的B+树就可以存放
1170*1170*16,也就是21902400条记录。而要查询一条记录,只需要3次磁盘IO就可以了。
B+树所有数据都存放在叶子节点,而非叶节点只存放索引数据,可以保证高扇出性,并且叶子节点之间通过双向链表进行链接,对range查询友好。
InnoDB中的聚集索引(clustered index)和辅助索引(secondary index),都是B+树,不同的是,聚集索引的叶子节点存放了记录的完整信息,而辅助索引的叶子节点只存放了索引列和主键数据。
一张表只有一个聚集索引,用于存放表数据,但是可以创建多个辅助索引,来加快查询。
聚集索引
InnoDB存储引擎表是索引组织表,即表中数据按照主键顺序存放。聚集索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放整张表的行纪录数据,所以也将聚集索引的叶子节点称为数据页。
如果用户建表时没有指定主键,那么会自动选择第一个NOT NULL的唯一索引作为表的主键,如果没有的话,会自动生成一列6byte的rowID。
辅助索引
辅助索引的叶子节点并不包含行记录的全部数据,只包含了包含索引列和聚集索引键,也就是表的主键。
当通过辅助索引来寻找数据时,如果辅助索引中没有包含本次查询的所有列数据时,需要通过主键到聚集索引去加载完整数据,这个过程称为回表查询。而如果辅助索引中,有本次查询的所有列数据,则可以直接返回数据,这种索引称为覆盖索引。
对于复合索引,比较的顺序是先比较第一列,再比较第二列,第三列…,因此,需要满足最左前缀匹配查询才能命中复合索引。
注意,假设联合索引(a, b, c) ,查询条件 a > xx and b > yy and c > zz ,只有 a 列可以用到索引,因为在所有大于 a 的数据中, b 并不是有序的,同理c也一样。
对于一些sql,我们可以通过创建复合索引,减少回表查询来进行优化。
mysql5.6还引入了索引条件下推(Index Condition Pushdown, ICP)来优化辅助索引的查询,该优化可以减少查询时的回表操作。比如复合索引中有些列,在查询条件中因为使用了like '%xx%',或者不满足最左前缀匹配而无法参与过滤,在以前需要回表查询整行记录(假设索引没有覆盖全部查询列),然后在server层进行过滤。而ICP,可以将这些列相关的查询条件下推到InnoDB存储引擎,在扫描索引的过程就进行过滤,从而减少server层和存储引擎的交互以及回表操作的次数,从而优化查询。
Cardinality
可以通过以下命令查看表的索引信息:
1 | mysql> show index from users\G; |
上面Cardinality值非常关键,查询时优化器会根据这个值来判断是否使用这个索引。但是这个值并不是实时更新的,因为实时更新的代价太大了。
首先,并不是所有查询条件中出现的列都要添加索引,索引并不是建的越多越好,因为索引的维护也是需要开销的。一般只有那些区分度比较高的列才加索引,对于像性别、地区、类型这些字段,取值范围很小,比如性别只有男和女,区分度并不高,称为低选择性,添加索引是完全没有必要的,要知道索引查询完之后还要回表查询完整的记录,这部分开销也是需要考虑进去的。
相反,如果某个字段的取值范围很广,比如用户名,几乎是唯一的,属于高选择性,建立索引是最合适的。
如何查看索引是否是高选择性的呢?可以通过SHOW INDEX结果中的Cardinality列来观察,该值表示索引中不重复记录数量的预估值,注意并不是一个准确值,在实际应用中,Cardinality/n_rows_in_table应该尽可能接近1,也就是尽可能没有重复,如果这个比值非常小,需要考虑是否还有必要创建这个索引。在访问高选择性的字段并从表中取出很少一部分数据时,对这个字段添加索引是非常有必要的。
那么mysql是如何来统计Cardinality的信息的呢?mysql中有各种不同的存储引擎,而每种存储引擎对B+树索引的实现又各不相同,因此对Cardinality的统计是放在存储引擎进行的。
在实际应用中,索引的更新操作可能是非常频繁的。如果每次索引更新的时候都更新Cardinality的统计,那么会给数据库带来很大的负担,另外如果一张表数据非常大,那么统计一次Cardinality所需要的时间可能非常长,这也是不能接受的。因此,数据库对于Cardinality的统计都是通过采样来完成的。
InnoDB中对Cardinality的更新策略为:
- 表中1/M的数据已经发生过变化
- stat_modified_counter>2 000 000 000
stat_modified_counter是innodb内部的一个计数器,用来表示发生变化的次数。
当统计Cardinality时,默认InnoDB会对N个叶子节点进行采样:
- 取得B+树索引中叶子节点的数据,记为A
- 随机选取N个叶子节点,统计每个页中不同记录的个数,即为P1, P2, P3, ……, Pn
- 根据采样信息给出估计值:
Cardinality = (P1+P2+P3+ ...... +Pn)*A/n
在mysql中,有两种存储索引统计的方式,可以通过参数innodb_stats_persisten值选择:
- 设置为on的时候,表示统计信息会持久化存储,这时,默认的N是20,默认的M是10
- 设置为off的时候,表示统计信息只存储在内存,这时,默认的N是8,M是16
根据上面的统计过程,我们可以知道:
- Cardinality值是通过对8个叶子节点预估而得的,不是一个实际精确的值
- 每次都是随机取8个叶子节点进行统计,因此前后两次统计的值可能是不同的,当使用
SHOW INDEX FROM table_name查看索引信息时,即会触发数据库对于Cardinality的统计,很可能前后两次结果中Cardinality值是不同的
前面说到,查询时优化器会根据Cardinality来判断是否使用这个索引。首先,优化器选择索引的目的是找到一个最优的执行方案,用最小的代价去执行查询,而扫描行数就是影响执行代价的因素之一,当然,还有其他的影响因素,优化器还会结合是否使用临时表,是否需要排序等因素来综合判断。优化器会根据索引的Cardinality来估计需要扫描的行数,而且还要考虑是否需要回表查询,这个代价也需要计算进去。回表查询的时候,数据是无序的,因此变成了随机读,因此当要求访问的数据量很大时(一般占整个表的20%左右),优化器会选择通过聚集索引来查找数据,因为顺序读要远快于随机读。
索引Hint
multi-range read优化
事务
- 隔离:mvcc,快照读
- 持久性:redo log,wal日志
- 回滚:undo log,实现事务回滚,还用于实现mvcc
- 并发控制:2pl,两阶段锁协议
隔离级别
锁
采用2pl
数据一致性问题,外键问题
mvcc
[TODO]具体实现